| Map
> Data Science > Predicting the Future >
Modeling > Clustering |
|
|
|
|
|
|
Clustering
|
|
|
| A cluster is a subset of
data which are similar. Clustering (also called unsupervised learning) is
the process of dividing a dataset into groups such that the members of each group are as
similar (close) as possible to one another, and different groups are as dissimilar
(far) as possible from one another. Clustering
can uncover previously undetected relationships in a dataset.
There are many applications for cluster analysis. For example, in
business, cluster analysis can be used to discover and characterize customer
segments for marketing purposes and in biology, it can be used for
classification of plants and animals given their features. |
|
|
| |
|
|
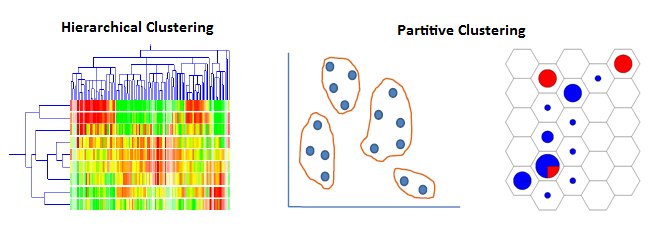
| Two main groups of clustering algorithms are: |
|
|
- Hierarchical
- Partitive
|
|
|
|
|
|
|
| A good clustering method requirements are: |
|
|
- The ability to discover some or all of the hidden clusters.
- Within-cluster similarity and between-cluster dissimilarity.
- Ability to deal with various types of attributes.
- Can deal with noise and outliers.
- Can handle high dimensionality.
- Scalable, Interpretable and usable.
|
|
|
| An important issue in clustering is how to determine the similarity between two objects, so that clusters can be formed from objects with
high similarity within clusters and low similarity between clusters. Commonly,
to measure similarity or dissimilarity between objects, a distance measure
such as Euclidean, Manhattan and Minkowski is used. A distance function
returns a lower value for pairs of objects that are more similar to one another. |
|
|
|

|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|