| Map
> Data Science > Predicting the Future >
Modeling > Classification/Regression >
ANN > Gradient Descent |
|
|
|
|
|
|
Gradient Descent
|
|
|
Gradient descent is an optimization algorithm
that minimizes functions. For a given function J
defined by a set of parameters
(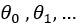 ), gradient descent
finds a local (or global) minimum by assigning an initial set of values to
the parameters and then iteratively keeps changing those values proportional to the negative of the gradient of the function. ), gradient descent
finds a local (or global) minimum by assigning an initial set of values to
the parameters and then iteratively keeps changing those values proportional to the negative of the gradient of the function. |
|
|
| |
|
|
| Simple Linear Regression using Least Squares |
|
|
| Linear regression is an
algorithm which uses ordinary least squares to model the linear relationship between a dependent variable (target) and one or more independent variables (predictors).
Simple linear regression (SLR) is a model with one single
independent variable. |
|
|
|
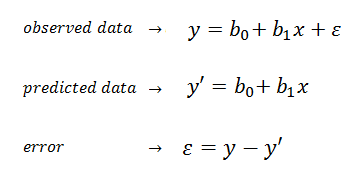
|
|
|
| Ordinary least squares (OLS)
is
a non-iterative method that fits a model such that the sum-of-squares of differences of observed and predicted values is minimized. |
|
|
|
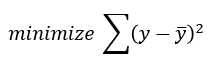
|
|
|
| The linear model parameters using OLS: |
|
|
|
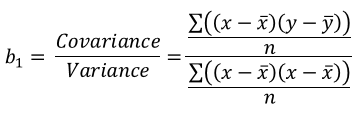
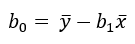
|
|
|
| Simple Linear Regression using
Gradient Descent |
|
|
|
Gradient descent finds the linear model parameters iteratively. |
|
|
|
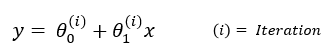
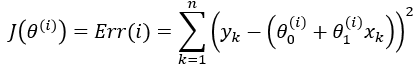
|
|
|
If we minimize function J, we will get the best line for our
data which means lines that fit our data better will result in lower
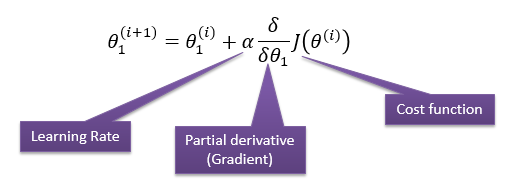
overall error. To run gradient descent on this error function, we first need to compute its gradient. The gradient will act like a compass and always point us downhill. To compute it, we will need to differentiate our error function. Since our function is defined by two parameters
(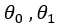 ), we will need to compute a partial derivative for each. These derivatives work out to be: ), we will need to compute a partial derivative for each. These derivatives work out to be: |
|
|
|
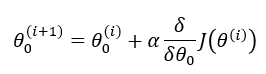
|
|
|
| The Learning Rate controls how large of a step we take downhill during each iteration. If we take too large of a step, we may step over the minimum. However, if we take small steps, it will require many iterations to arrive at the minimum. |
|
|
|
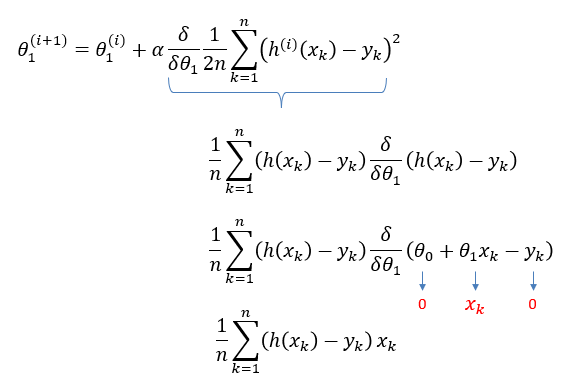
Finally:
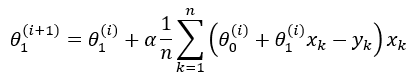
|
|
|
| And this is the final equation for
updating the intercept iteratively. |
|
|
|
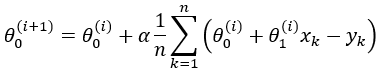
|
|
|
| Now we have what needed to run gradient descent.
First we initialize our search to start at any pair of
values and then let the gradient descent algorithm march downhill on our error function towards the best line. Each iteration will update
to a line that yields slightly lower error than the previous iteration. The direction to move in for each iteration is calculated using the two partial derivatives from above. A good way to ensure that gradient descent is working correctly is to make sure that the error decreases for each iteration. |
|
|
|
|
|
| Non-linear Gradient Descent |
|
|
The concept of minimizing a cost function to tune parameters applies
not only to linear models but also to non-linear models. For example, the
following is the cost function logistic regression.
|
|
|
|
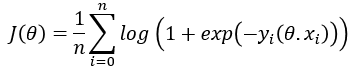
|
|
|
|
|
|
|
Convergence |
|
|
| How to determine when the search finds a
solution? This is typically done by looking for small changes in error iteration-to-iteration (e.g., where the gradient is near zero). |
|
|
| |
|
|
|
Convexity |
|
|
| Not all problems have only one minimum
(global minima). It is possible to have a problem with local minima where a gradient search can get stuck in. |
|
|
| |
|
|
| demo |
|
|