| Map > Problem Definition > Data Preparation > Data Exploration > Modeling > Evaluation > Clustering |
Evaluation - Clustering |
| I. Data Preparation |
|
1- Load libraries |
|
library(data.table) library(formattable) library(plotrix) library(dplyr) library(Rtsne) library(MASS) library(xgboost) library(factoextra) library(caTools) library(pROC) library(caret) library(gains) library(lift) library(cluster) |
|
2- Read Expressions file |
|
df <- read.csv("GSE74763_rawlog_expr.csv") df2 <- df[,-1] rownames(df2) <- df[,1] expr <- transpose(df2) rownames(expr) <- colnames(df2) colnames(expr) <- rownames(df2) dim(expr) |
|
3- Read Samples file |
|
targets <- read.csv("GSE74763_rawlog_targets.csv") colnames(targets) dim(targets) |
|
4- Merge Expressions with Samples |
|
data <- cbind(expr, targets) colnames(data) dim(data) |
| II. Hierarchical Clustering (Determining Optimal Clusters) |
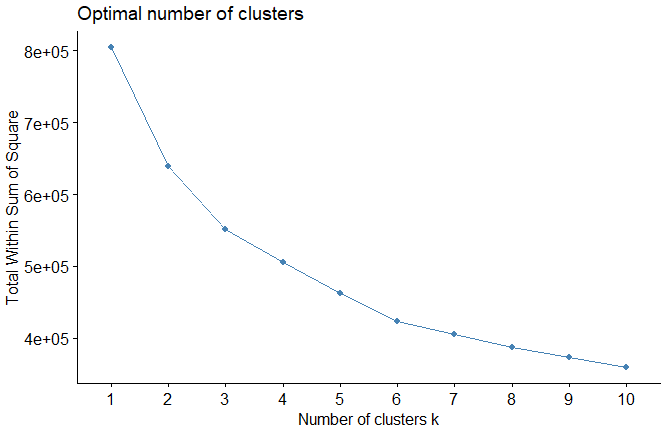
| 1- Elbow Method |
| fviz_nbclust(expr, FUN = hcut, method = "wss") |
|
|
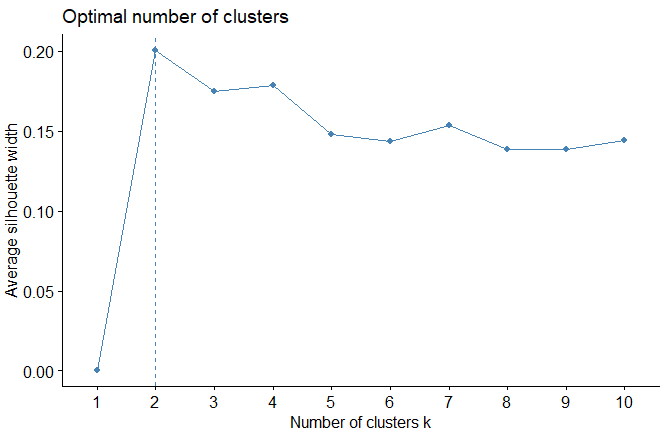
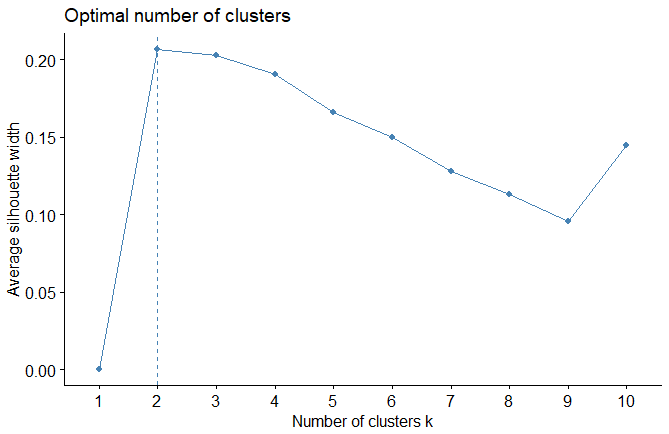
| 2- Average Silhouette Method |
| fviz_nbclust(expr, FUN = hcut, method = "silhouette") |
|
|
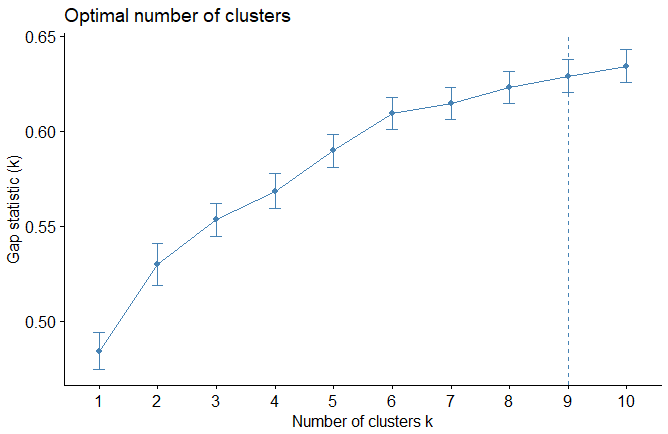
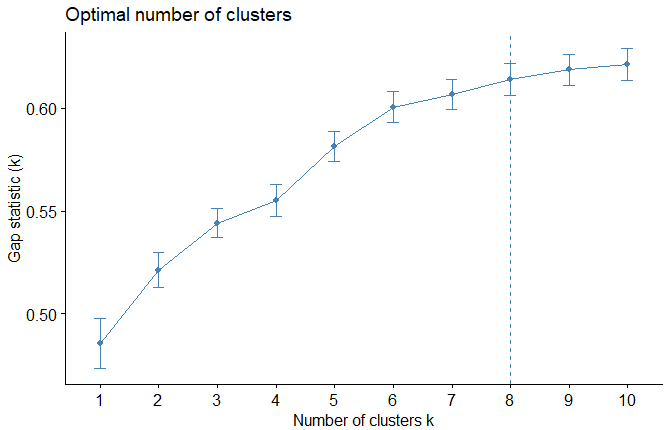
| 3- Gap Statistic Method |
|
gap_stat <- clusGap(expr, FUN = hcut,
nstart = 25, K.max = 10, B = 50) fviz_gap_stat(gap_stat) |
|
|
| III. K-Means Clustering (Determining Optimal Clusters) |
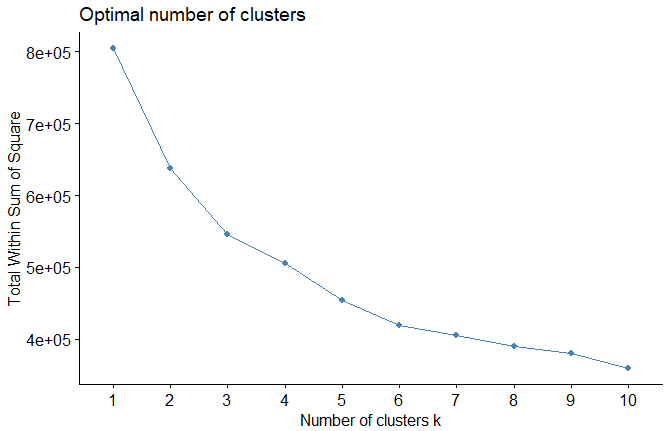
| 1- Elbow Method |
| fviz_nbclust(expr, FUN = kmeans, method = "wss") |
|
|
| 2- Average Silhouette Method |
| fviz_nbclust(expr, FUN = kmeans, method = "silhouette") |
|
|
| 3- Gap Statistic Method |
|
gap_stat <- clusGap(expr, FUN =
kmeans,
nstart = 25, K.max = 10, B = 50) fviz_gap_stat(gap_stat) |
|
|