| Map
> Problem Definition > Data Preparation
> Data Exploration >
Modeling > Evaluation
> Deployment |
|
|
Data Preparation
|
| Data preparation is about constructing a dataset
from one or more data sources to be used for exploration and modeling. It is
a solid practice to start with an initial dataset to get familiar with the
data, to discover first insights into the data and have a good understanding
of any possible data quality issues. Data preparation is often a time
consuming process and heavily prone to errors. The old saying
"garbage-in-garbage-out" is particularly applicable to those data science
projects where data gathered with many invalid, out-of-range and missing
values. Analyzing data that has not been carefully screened for such
problems can produce highly misleading results. Then, the success of data
science projects heavily depends on the quality of the prepared data. |
|
|
| Multi-omics Data Preparation |
| Multi-omics techniques (e.g., RNA-Seq) have
a wide variety of applications, but no single analysis pipeline can be used
in all cases. The following pipeline is a review all of the major steps in
RNA-Seq data analysis, including experimental design, quality control, read
alignment, quantification of gene and transcript levels, visualization,
differential gene expression, alternative splicing, functional analysis and
more. Our focus will only be on the "Core-analysis" step. |
| |
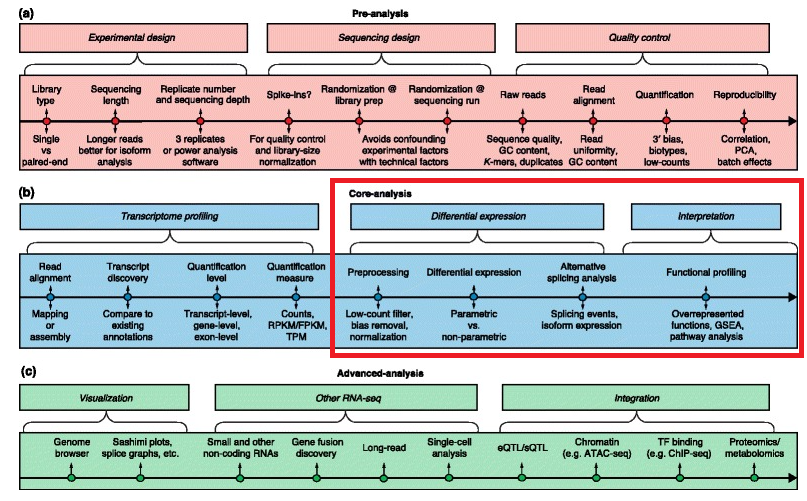 |
|
A
generic roadmap for RNA-Seq computational analyses |
|
|
| Public Multi-omics Data Sources: |
|
GEO
: GEO is a public functional genomics data repository supporting MIAME-compliant
data submissions. Array- and sequence-based data are accepted. Tools are
provided to help users query and download experiments and curated gene
expression profiles. |
|
ArrayExpress : ArrayExpress Archive of Functional Genomics Data stores
data from high-throughput functional genomics experiments, and provides
these data for reuse to the research community. |
|
TCGA : The Cancer Genome Atlas (TCGA), a landmark cancer genomics
program, molecularly characterized over 20,000 primary cancer and matched
normal samples spanning 33 cancer types. This joint effort between NCI and
the National Human Genome Research Institute began in 2006, bringing
together researchers from diverse disciplines and multiple institutions. |
|
ADDI : The
Alzheimer’s Disease Data Initiative (ADDI) is on a mission to fundamentally
transform Alzheimer’s disease (AD) research. Through a data sharing
platform, data science tools, funding opportunities, and global
collaborations, ADDI is advancing scientific breakthroughs and accelerating
progress towards new treatments and cures for AD and related dementias. |
|
ADNI : Alzheimer's
Disease Neuroimaging Initiative is a multisite study that aims to improve
clinical trials for the prevention and treatment of Alzheimer’s disease. |
|
DepMap : The goal
of the Dependency Map (DepMap) portal is to empower the research community
to make discoveries related to cancer vulnerabilities by providing open
access to key cancer dependencies analytical and visualization tools. |
|
PPMI : PPMI is a landmark study collaborating with partners around the
world to create a robust open-access data set and biosample library to speed
scientific breakthroughs and new treatments. |
| |
| |