| Map
> Data Science > Predicting the Future >
Modeling > Association Rules |
|
|
|
|
|
|
Association Rules
|
|
|
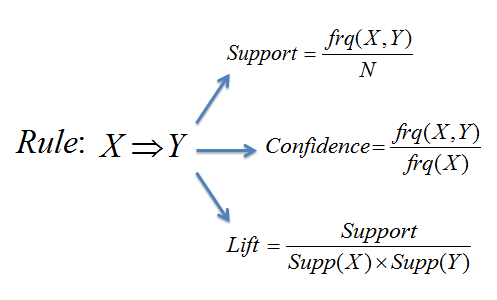
| Association Rules find all sets of items (itemsets) that have support
greater than the minimum support and then using the large itemsets to generate the desired rules that have
confidence greater than the minimum confidence. The lift of a rule is the ratio of the observed support to that expected if X and Y were independent.
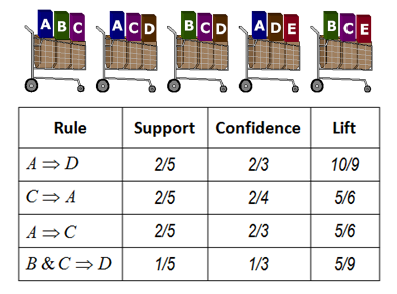
A typical and widely used example of association rules application is
market basket analysis. |
|
|
|
|
|
|
| Example: |
|
|
|
|
|
|
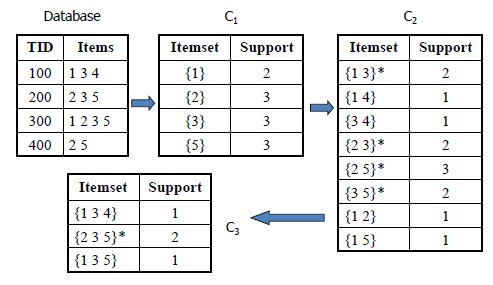
| AIS Algorithm |
|
|
- Candidate itemsets are generated and counted on-the-fly as the database is scanned.
- For each transaction, it is determined which of the large itemsets of the previous pass are contained in this transaction.
- New candidate itemsets are generated by extending these large itemsets with other items in this transaction.
|
|
|
|
|
|
|
|
The disadvantage of the AIS algorithm is that it results in unnecessarily generating and counting too many candidate itemsets that turn out to be small.
|
|
|
|
|
|
|
|
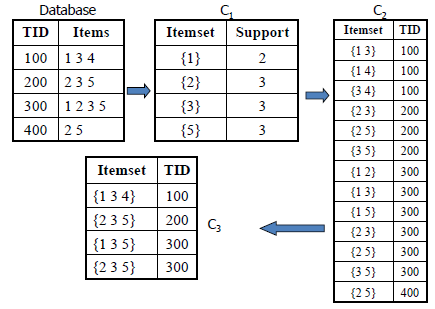
SETM Algorithm
|
|
|
- Candidate itemsets are generated on-the-fly as the database is scanned, but counted at the end of the pass.
- New candidate itemsets are generated the same way as in AIS algorithm, but the TID of the generating transaction is saved with the candidate itemset in a sequential structure.
- At the end of the pass, the support count of candidate itemsets is determined by aggregating this sequential structure.
|
|
|
|
|
|
|
|
The SETM algorithm has the same disadvantage of the AIS algorithm.
Another disadvantage is that for each candidate itemset, there are as many entries as its support value.
|
|
|
|
|
|
|
|
Apriori Algorithm
|
|
|
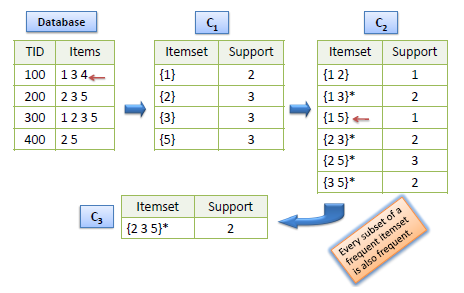
- Candidate itemsets are generated using only the
large itemsets of the previous pass without considering the transactions in the database.
- The large itemset of the previous pass is joined with itself to generate all
itemsets whose size is higher by 1.
- Each generated itemset that has a subset which is not
large is deleted. The remaining itemsets are the candidate ones.
|
|
|
|
|
|
|
|
The Apriori algorithm takes advantage of the fact that any subset of a frequent itemset is also a frequent
itemset. The algorithm can therefore, reduce the number of candidates being considered by only exploring the itemsets whose support count is greater than the minimum support count. All infrequent itemsets can be pruned if it has an infrequent subset. |
|
|
| |
|
|
| AprioriTid Algorithm
|
|
|
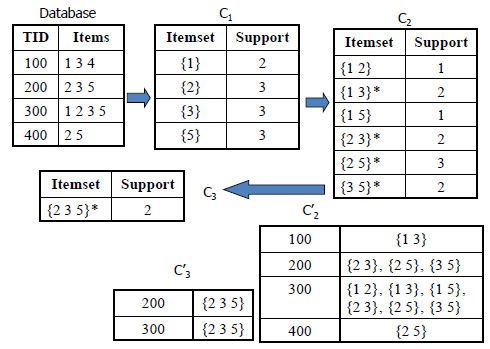
- The database is not used at all for counting the support of candidate itemsets after the first pass.
- The candidate itemsets are generated the same way as in Apriori algorithm.
- Another set C’ is generated of which each member has the TID of each transaction and the large itemsets present in this transaction. This set is used to count the support of each candidate
itemset.
|
|
|
|
|
|
|
| The advantage is that the number of entries in C’ may be smaller than the number of transactions in the database, especially in the later passes. |
|
|
| |
|
|
| AprioriHybrid Algorithm
|
|
|
| Apriori does better than AprioriTid in the earlier passes.
However, AprioriTid does better than Apriori in the later passes. Hence, a hybrid algorithm can be designed that uses Apriori in the initial passes and switches to AprioriTid when it expects that the set C’ will fit in memory. |
|
|
| |
|
|
|
|
|
|
|
|
|
|
|
|
